微软Phi-4封神,14B小模型数学击败GPT-4o,合成数据占比40%,36页技术报告出炉
关注+2024-12-23作者:教学助手
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。
140亿参数,40%合成数据,年度SLM之王诞生!
最近,微软下一代小模型Phi-4正式亮相。在GPQA和MATH基准上,其数学性能直接碾压GPT-4o、Gemini Pro1.5。
而且,Phi-4粉碎了其他小模型,与Llama-3.3-70B-Instruct的性能不相上下。
fmAiaaKrFKMaBFeMIEaWeujZZ1ic0kbeckIHNTjAPOnKlED1J42bztetVIHxYYqOEXlD1ZenJP4A/640?wx_FMt=png&from=appmsg" data-type="png" data-w="1080" data-width="1278" data-original-="" data-index="2" src="https://pic.chinaz.com/2024/1223/2024122308555506180.jpg" _width="100%" alt="图片" data-fail="0" style="margin: 0px auto; padding: 0px; box-sizing: border-box; outline: 0px; border: 1px solid rgb(238, 238, 238); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; max-width: 700px; background: url("../img/bglogo2.svg") center center no-repeat rgb(247, 248, 249); box-shadow: rgba(27, 95, 160, 0.1) 0px 1px 3px; display: inline-block;"/>
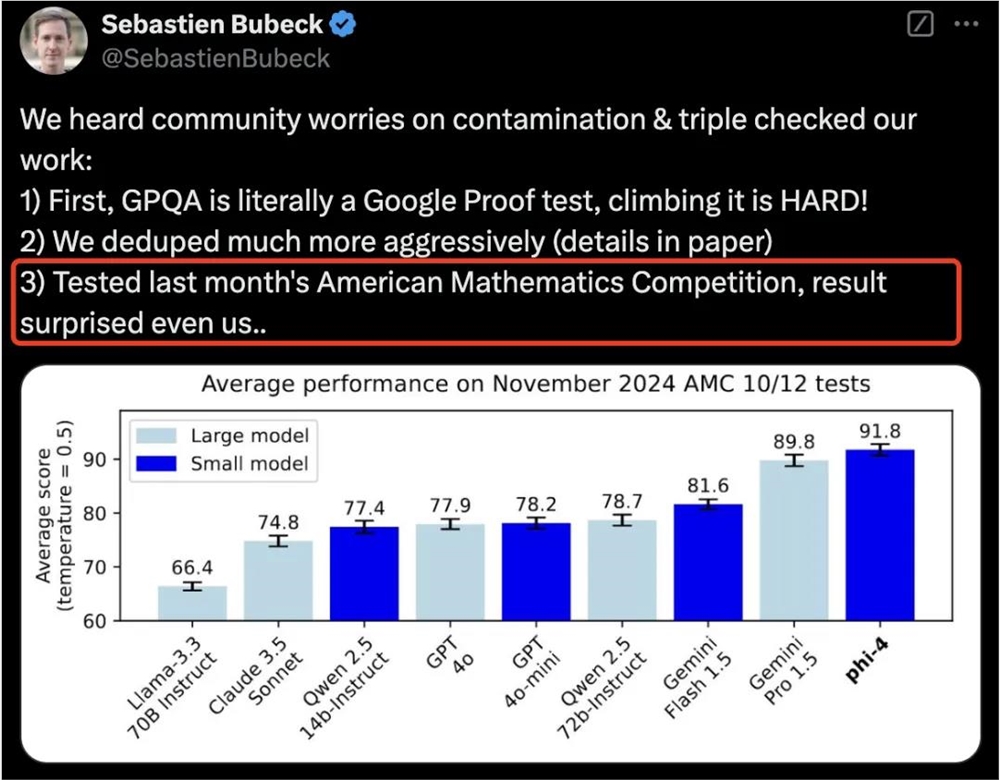
甚至,在2024ACM数学竞赛问题上,Phi-4取得了91.8%准确率。
Phi系列前负责人Sebastien Bubeck看到这个结果后,感到非常惊讶。
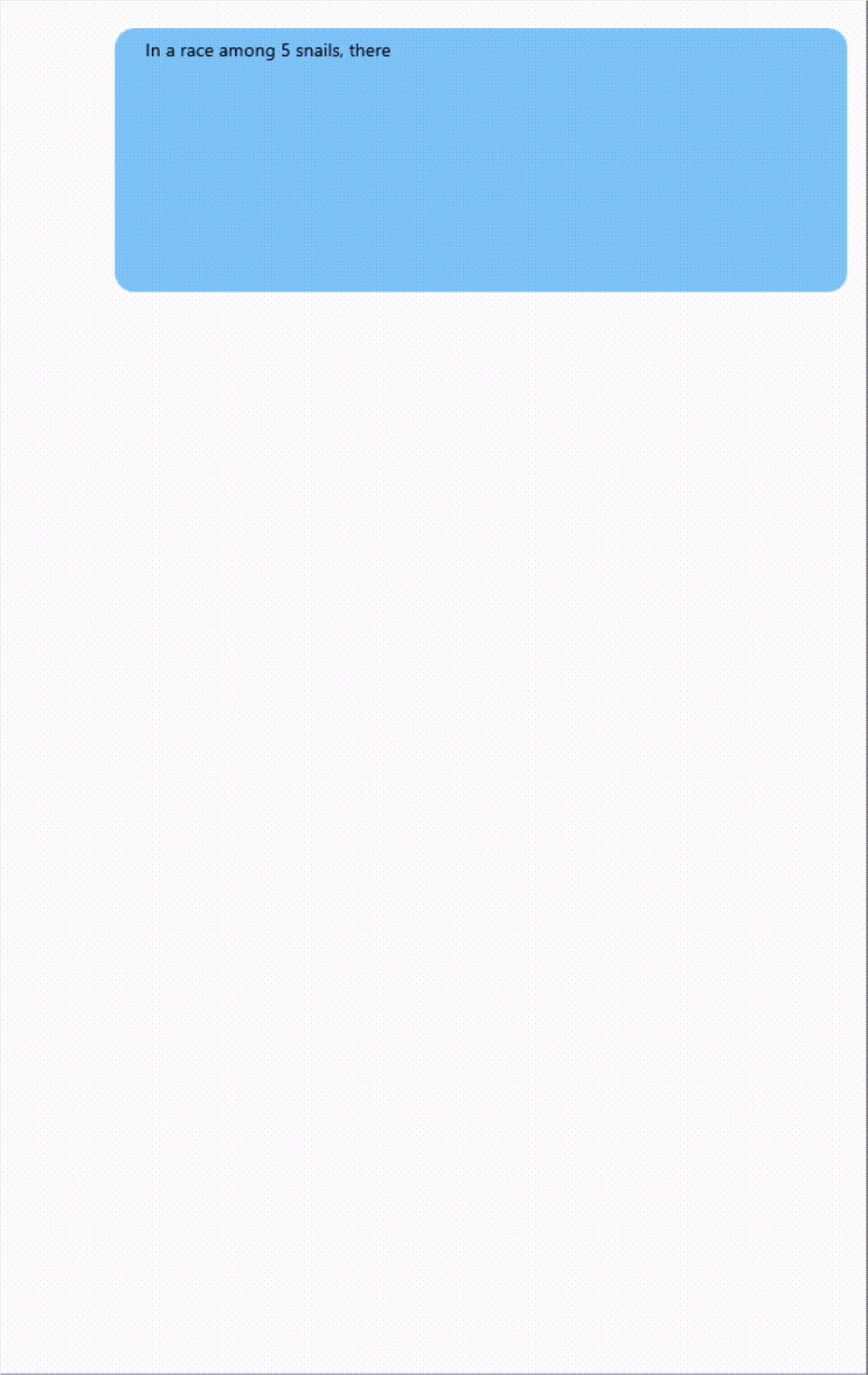
下面这个例子,展示了Phi-4在数学推理方面的能力,不仅神速还准确。
深挖背后,Phi-4继承了Phi系列前几代的传统,同样是在教科书级别的「合成数据」上完成了训练。
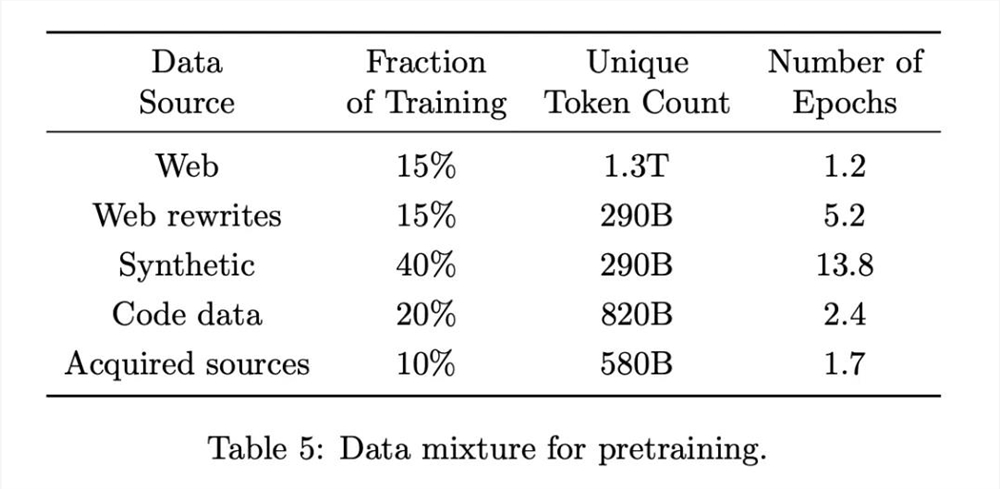
合成数据比例高达40%
除了合成数据,它共实现了三大核心技术突破,包括精选的原生数据,以及领先的后训练技术,如DPO中的关键token搜索(Pivotal Tokens Search)。
Phi-4的成功,从侧面推翻了Ilya、Alexander Wang多位大佬宣称的「数据墙」的观点。

目前,新模型在微软Azure AI Foundry上提供,下周将在HuggingFace上线。
数学击败GPT-4o,36页技术报告出炉
Phi-4与大多数语言模型不同,那些模型的预训练主要基于诸如网络内容或代码这类自然产生的数据来源,而Phi-4则有策略地在整个训练过程中融入了合成数据。
虽然Phi系列先前的模型表现主要来源于蒸馏了教师模型(特别是GPT-4)的能力,但Phi-4在STEM领域的问答能力上显著超越了其教师模型,证明了数据生成和后训练技术比模型蒸馏更能带来能力上的提升。

论文地址:https://arxiv.org/abs/2412.08905
Phi-4主要是由三部分核心技术构成:
- 预训练和中训练的合成数据
- 高质量有机数据的筛选和过滤
- 后训练
得益于这些创新,Phi-4在推理相关任务上的性能与更大的模型相当,甚至超越它们。
例如,在许多广泛使用的推理相关基准测试中,其性能达到或超过了Llama-3.1-405B。
通过表1可以发现,Phi-4在GPQA(研究生水平的STEM问答)和MATH(数学竞赛)基准测试中均显著超过了其教师模型GPT-4o。
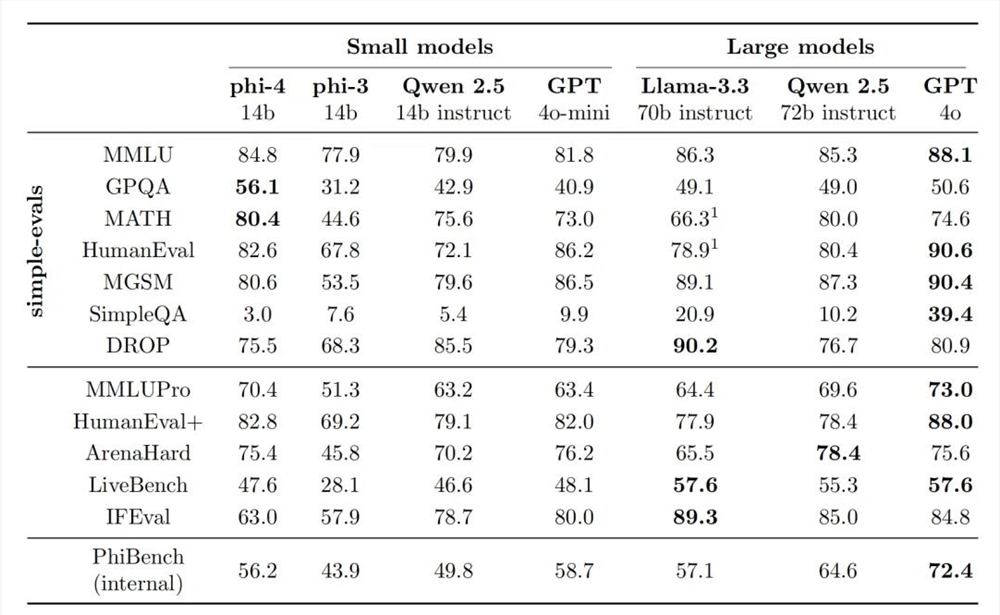
表1Phi-4在经典基准测试上的表现
为了验证Phi-4是否存在过拟合和数据污染问题,研究者在2024年11月的AMC-10和AMC-12数学竞赛上测试了该模型。
这两场竞赛中的数据均未曾在训练时被收集过,所以其竞赛表现可以有效地作为检验模型泛化性能的指标。
从下图中可以看出,Phi-4虽然仅仅只有14B,但是其平均得分甚至大幅超过了其教师模型GPT-4o。
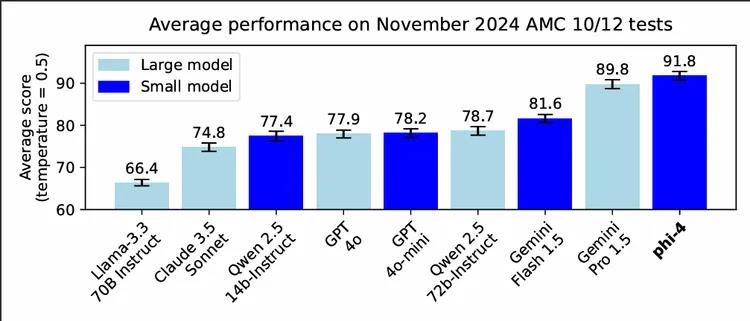
Phi-4在数学竞赛问题上优于许多更大的模型,包括Gemini Pro1.5
合成数据的优势
合成数据构成了Phi-4训练数据的大部分,其通过多种技术生成,包括多智能体提示(multi-agent prompting)、自修订工作流(self-revision workflows)和指令反转(instruction reversal)。
这些技术方法能够构建促使模型具备更强推理和问题解决能力的数据集,解决了传统无监督数据集中的一些弱点。
合成数据不是有机数据的廉价替代品,而是相对于有机数据具有几个直接优势。
数据结构化和支持渐进式学习
在有机数据集中,token之间的关系往往复杂且间接。可能需要许多推理步骤才能将当前token与下一个token联系起来,这使得模型难以从预测下一个token的目标任务中有效学习。
相比之下,由于从语言模型生成的每个token都是根据前面的token预测而来的,而这样结构化的token也可以让模型的训练变得更加高效。
将训练与推理上下文对齐
合成数据可以规避掉模型从有机数据集中学习到一些并不适合后续训练的数据特性。
比如说,网络论坛往往有着自身特定的交流风格、用语习惯等,而人们与大模型对话时,其语言风格、交互逻辑又是另外一种情况。
此时如果直接采用网络论坛的数据进行训练,假设有一些内容的风格比较独特,模型就会认为在对话中该内容出现的几率会很低。因此在后续对话中模型进行推理时,便不能将对话内容精准匹配到对应的论坛内容上去。
而合成数据会将网络论坛中的内容改写成与LLM交互时的语言风格,使得其在LLM聊天推理的上下文中更容易匹配。
合成数据在Phi-4的后训练中也发挥着关键作用,其中采用了诸如拒绝采样和直接偏好优化(DPO)的新方法来优化模型的输出。
合成数据的来源
预训练和训练中数据
为此,研究团队创建了50种广泛的合成数据集类型,每个数据集都依赖于不同的种子和不同的多阶段提示程序,涵盖了各种主题、技能和交互性质,累计约4000亿个无权重的token。
通过以下方法,他们确保了合成数据并不被一些低质量的网络数据所污染,从而成为高质量训练数据集。
种子数据集的构建
1. 网页和代码种子:从网页、书籍和代码库中提取摘录和代码片段,重点关注具有高复杂性、推理深度和教育价值的内容。为确保质量,团队采用两阶段筛选流程:首先,识别需要关注的重点高价值页面,其次,将选定的页面分割成段落,并对每个段落的客观和推理内容进行评分。
2. 问题数据集:从网站、论坛和问答平台上收集了大量问题。然后使用投票技术对这些问题进行筛选以平衡难度。具体来说,团队为每个问题生成多个独立的答案,并应用多数投票来评估答案的一致性。然后丢弃所有答案都一致(表明问题太简单)或答案完全不一致(表明问题太难或模糊)的问题。
3. 从多种来源创建问答对:利用语言模型从书籍、科学论文和代码等有机来源中提取问答对。这种方法不仅仅依赖于在文本中识别显式的问答对。相反,它涉及一个旨在检测文本中的推理链或逻辑进程的pipeline。语言模型识别推理或问题解决过程中的关键步骤,并将它们重新表述为问题和相应的答案。实验表明,如果操作得当,在生成内容上进行训练(在学术和内部基准上的改进方面)可以比在原始内容上进行训练更加有效。
重写和增强:种子通过多步骤提示工作流程转化为合成数据。这包括将给定段落中的大部分有用内容重写为练习、讨论或结构化推理任务。
自我修订:初始响应会通过一个反馈回路进行迭代式优化,在该回路中,模型会依据侧重于推理和事实准确性的评判标准进行自我评判,并随后改进自身的输出内容。
指令反转用于代码和其他任务:为了提高模型从指令生成输出的能力,团队采用了指令反转技术。例如,他们从代码数据语料库中选取现有的代码片段,并利用它们生成包含问题描述或任务提示的相应指令。只有原始代码和根据生成指令而重新生成的代码之间相似度高的指令才会被保留,以确保指令与输出内容相匹配。
后训练数据
在后训练阶段中,数据集主要由两部分组成:
- 监督微调(SFT)数据集:使用从公开数据集和合成数据中精心筛选的用户提示,再生成多个模型响应,并使用基于LLM的评估过程选择最佳响应。
- 直接偏好优化(DPO):基于拒绝采样和LLM评估生成DPO对,其中部分基于创建关键词token对的方法。
研究者利用生成的SFT数据和DPO数据对,来缓解模型的幻觉问题。
如下图6结果显示,这种方法大大减少了SimpleQA中的幻觉现象。
qqEBgCgTmPH7zGZYoQ/640?wx_fmt=png&from=appmsg" data-type="png" data-w="1080" data-width="2196" data-original-="" data-index="10" src="https://pic.chinaz.com/2024/1223/2024122308555506218.jpg" _width="100%" alt="图片" data-fail="0" style="margin: 0px auto; padding: 0px; box-sizing: border-box; outline: 0px; border: 1px solid rgb(238, 238, 238); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; max-width: 700px; background: url("../img/bglogo2.svg") center center no-repeat rgb(247, 248, 249); box-shadow: rgba(27, 95, 160, 0.1) 0px 1px 3px; display: inline-block;"/>
预训练
Phi-4同样基于Transformer架构构建,具有14B参数和默认的上下文长度4096。在训练中期,扩展到16K上下文。
由于预训练模型不擅长遵循指令,因此使用需要答案采用特定格式(例如简单评估)的零样本评估不是很有参考价值。
因此,团队采用了内部实现的基准测试进行预训练评估,该基准测试对各种任务使用混合的对数似然与少量样本提示。
具体来说,他们对 MMLU(5-shot)、MMLU-pro和ARCC(1-shot)使用对数似然评估,而对TriviaQA(TQA)、MBPP、MATH和GSM8k分别使用1、3、4和8个少样本的示例,以帮助模型遵循答案格式。

表2phi-4较phi-3-medium在预训练后基准测试评估的提升值
在长上下文基准HELMET测试中,Phi-4在召回率、最大上下文等指标上,几乎取得了领先的优势。
VR0qrsq4aLic8icQtcfEcdI09yLJDeMEpow/640?wx_fmt=png&from=appmsg" data-type="png" data-w="1080" data-width="1340" data-original-="" data-index="12" src="https://pic.chinaz.com/2024/1223/20241223085555062110.jpg" _width="100%" alt="图片" data-fail="0" style="margin: 0px auto; padding: 0px; box-sizing: border-box; outline: 0px; border: 1px solid rgb(238, 238, 238); --tw-shadow: 0 0 #0000; --tw-ring-inset: var(--tw-empty, ); --tw-ring-offset-width: 0px; --tw-ring-offset-color: #fff; --tw-ring-color: rgba(41, 110, 228, 0.5); --tw-ring-offset-shadow: 0 0 #0000; --tw-ring-shadow: 0 0 #0000; max-width: 700px; background: url("../img/bglogo2.svg") center center no-repeat rgb(247, 248, 249); box-shadow: rgba(27, 95, 160, 0.1) 0px 1px 3px; display: inline-block;"/>
后训练
如前所述,在后训练阶段过程中,最重要的一个技术是关键token搜索(PTS),那么这究竟是什么呢?
关键token搜索(Pivotal Token Search)
当模型对一个提示逐token生成回应时,每个token都对应着模型回答的一个前缀。
对于每个这样的前缀,可以考虑两个关键token:一是在改前缀下,模型回答正确的条件概率;另一个是该token带来的概率增量,即生成这个token前后正确率的差值。
其实,在AI模型生成答案时,往往只有少数几个关键token决定了整个答案的正确与否。
在研究中,团队观察到一个有趣的现象是:当模型在解答数学问题时,仅仅生成了negative关键token,就让原本可能失败的解答转向了成功。
而随后,它生成了(a token又可能让正确率急剧下降。

现在,将这个方法与DPO训练方法结合思考后,发现了几个值得注意的问题。
如上图3所示,实验中有许多token概率远低于关键token「negative」的0.31,这些token会在训练中产生噪声,稀释来自关键token的有效信号。
更糟糕的是,像(a这样导致解题不稳定的token,反而会因其低概率(0.12)收到强烈的正向学习信号。
此外,直觉表明,当两个文本内容出现实质性偏差时,比较它们各自下一个token概率(DPO的做法)可能失去意义。
总之,更有意义的信号,应该来自于文本开始偏离时的首批token。
为了缓解之前的问题,微软团队提出了一种创新的方法――关键token搜索(PTS)。
这个方法专门针对单个关键token生成偏好数据,在使用DPO优化效果精准作用于特定token。
PTS的核心任务是,在完整的token序列(T_full = t1, t2, ...)中找出那些关键token。
具体来说,它需要找出那些能显著影响成功率的token的位置,即p(success | t1, ..., ti)。
PTS会将发现的关键token转化为训练数据,先将Q + t1, ..., ti-1作为查询基准,再选择能提高/降低成功率的单个token分别作为「接受」和「拒绝」的样本。
虽然PTS使用的二分查找算法不能保证找出所有的关键token,但它具有两个重要特性。
- 找到的一定是关键token
- 如果成功概率再解题过程中接近单调变化,则能找出所有关键token
下图5所示,是使用PTS生成的偏好数据的示例。

在数学问答示例中,研究发现了一个有趣的现象,关键token往往不是明显的错误,而是引导模型走向不同解题路径的选择点。
比如,方法A――分别乘以分母;方法B――直接交叉相乘。
虽然这两种方法在数学上都是正确的,但对于模型来说,往往后者更加稳健。
通过PTS生成的训练数据,可以帮助Phi-4在这些关键决策点上做出更优的选择。
以小博大,Phi-4赢麻了
基于以上技术的创新,Phi-4才能在各项基准测试中展现出惊艳的一面。
上表1中,相较于同级别的Qwen-2.5-14B-Instruct模型,在12个基准测试中,Phi-4在九项测试中赢得优势。
而且,研究人员认为Phi-4在SimpleQA上的表现实际上比Qwen更好。
事实上,他们的基础模型在SimpleQA上获得了比Qwen-2.5-14B-Instruct更高的基准分数,只不过团队在后训练中有意修改了模型的行为,以优化用户体验而不是追求更高的基准分数。
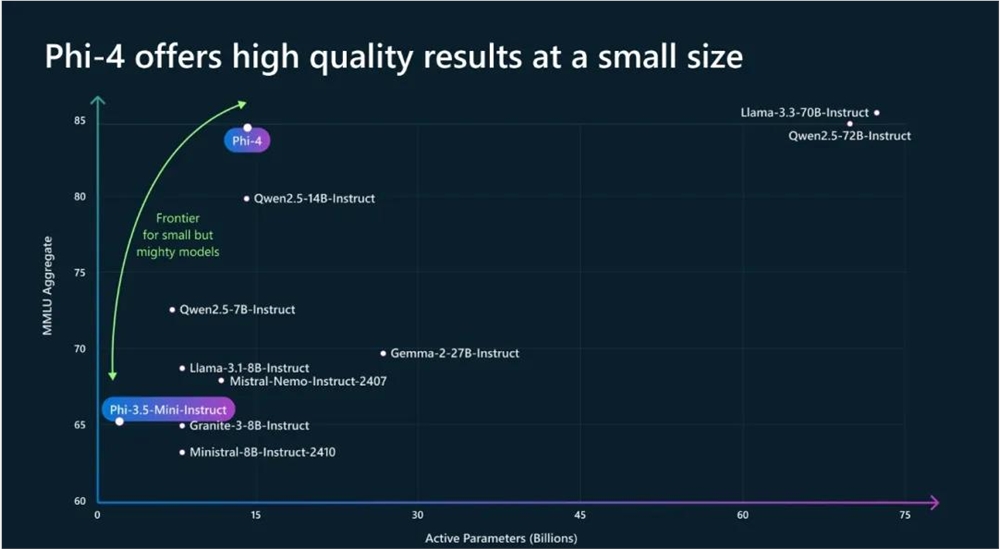
此外,Phi-4在STEM问答任务上展现出卓越的实力。
比如,在GPQA(研究生水平的STEM问题)和MATH(数学竞赛)上,它甚至超过了其教师模型GPT-4。
在HumanEval和HumanEval+衡量的编码能力方面,它也比任何其他开源模型(包括更大的Llama模型)得分更高。
而Phi-4表现欠佳的领域,分别在SimpleQA、DROP和IFEval上。
至于前两个,研究人员认为simple-evals报告的数字过于简化,并不能准确反映模型在基准问题上的表现。
然而,IFEval揭示了Phi-4的一个真实的弱点――在严格遵循指令方面存在困难。
在未来下一步研究中,研究人员相信通过有针对性的合成数据,让Phi系列模型的指令跟随性能得到显著改善。
接下来,还真有点期待,下一个Phi系列小模型的发布了。